Disclosure: some links in this article are affiliate links. If you sign up through one, HeroHunt may earn a commission at no extra cost to you.
The practical 2026 playbook for turning a name, email, photo, or username into the right person's social profiles, without crossing legal or ethical lines.
A single username now resolves to accounts across more than 3,000 websites in seconds, and one uploaded face can be matched against an index of roughly 3 billion open-web images. Finding someone's social media presence used to be a manual hunt through search boxes. In 2026 it is a software problem, and the software has gotten very good.
The shift matters because the tools split into camps that behave very differently. Free username scanners, paid people-search subscriptions, facial-recognition engines, commercial link-analysis platforms, and a new generation of autonomous AI agents all promise to "find anyone," but they pull from different data, carry different price tags, and expose you to very different legal risk. Picking the wrong one wastes money or, worse, produces a confident match that points at the wrong human being.
The single biggest mistake people make is trusting the match. Modern face search and AI deep-research agents are powerful enough to feel authoritative and unreliable enough to ruin a decision. Police have wrongfully jailed people on uncorroborated facial-recognition hits, and frontier language models fabricate profile URLs at measurable rates. This guide treats every automated result as a lead to verify, never as proof.
This is written for legitimate use: recruiters and sourcers, sales teams, trust-and-safety and fraud investigators, journalists, due-diligence analysts, and anyone trying to reconnect or confirm an identity. It covers the full landscape from free open-source tools to enterprise platforms, the exact pricing, the step-by-step workflow, where each approach fails, and the privacy and legal lines you must not cross.
Written by Yuma Heymans (@yumahey), who built HeroHunt.ai and has spent the last several years building AI that resolves a person's profiles across LinkedIn, GitHub, and the open web. He writes here from hands-on experience with the same identity-matching problem these tools try to solve.
Contents
- The 2026 Landscape: How AI Finds People Now
- The Identifier Pivot: The Core Workflow
- People-Search Engines and Identity Aggregators
- Reverse Image and Face Search
- Username and Email OSINT Tools (Free and Open Source)
- Commercial OSINT and Link-Analysis Platforms
- AI Agents and Autonomous Profile Discovery
- Cross-Platform Sourcing for Recruiters and Sales
- Platform by Platform: LinkedIn to Bluesky
- Verification: Turning a Match Into a Confirmed Identity
- Accuracy, Limitations, and Failure Modes
- Privacy, Legal, and Ethical Guardrails
- The Future: Agentic OSINT and Decentralized Identity
- Putting It Together: Which Approach to Use When
1. The 2026 Landscape: How AI Finds People Now
The fastest way to understand the field is to see it as three overlapping markets that happen to do the same job from different angles. Facial-recognition engines start from a photo, people-data and sales-intelligence platforms start from a name or email, and open-source OSINT tools start from a username. AI has crept into all three, but the most consequential change in 2026 is that the tools no longer just return a list of links. They reason across sources, score confidence, and increasingly act on their own. The practical result is that "find this person's profiles" has become a natural-language request rather than a sequence of manual searches.
This consolidation is happening on top of a genuinely large and fast-growing industry. The open-source intelligence market, the engine behind most automated profile discovery, is sized at about $22.95 billion in 2026, up from $18.07 billion a year earlier and growing roughly 27% annually toward $60 billion by 2030 - The Business Research Company. Facial recognition adds another $10.69 billion market in 2026, and sales intelligence, identity resolution, and AI recruitment each contribute multibillion-dollar slices of their own - Precedence Research. The money is flowing because the demand is real and mainstream, not niche.
To see the relative scale of the segments that all converge on "finding people," the comparison below puts 2026 market sizes side by side. The point is not the precise figure (analysts disagree by billions) but the shape: OSINT and facial recognition dwarf the more specialized recruiting and identity-resolution tools, which tells you where the heaviest investment and fastest innovation are concentrated.
2026 Market Size by Segment (USD Billions)
What the chart understates is how fast the smaller segments are moving. The AI-in-recruitment market alone is projected to grow from about $872 million in 2025 to nearly $6 billion by 2034 at a 23.8% compound rate - TrendX Insights. Adoption tells the same story: SHRM's 2025 research found 69% of HR professionals now use AI to support recruiting, up from 51% the year before, with candidate sourcing the top use case - SHRM. When two-thirds of an entire profession adopts a workflow in a single year, the tools stop being experimental and start defining how the job is done.
The other defining feature of the 2026 landscape is the legal overhang. Facial-recognition scraping is now explicitly restricted in Europe, biometric privacy laws carry per-violation damages in several US states, and using a people-search report to make a hiring decision can trigger federal consumer-protection rules. The capability has outrun the regulation in some places and collided with it in others, which is why the most valuable skill is not running the tools but knowing which ones you are actually allowed to use for your purpose.
2. The Identifier Pivot: The Core Workflow
Before any specific tool, understand the workflow that every effective searcher uses, because the tools are just accelerators for it. The core technique is the identifier pivot: you start with one weak data point and convert it into a stronger one, then repeat. A name becomes a username, a username becomes a set of profiles, a profile yields an email, an email confirms the username, and a photo ties it all to a real face. Each pivot both widens your coverage and tightens your confidence that you have the right person.
This works because of a simple behavioral fact: people are creatures of habit online. The widely cited rule of thumb is that the average person reuses the same handle across three to five platforms, which is why a username is often your single highest-yield starting point - OSINT Industries. Reused handles, recycled profile photos, and the same recovery email stitched across accounts are the seams that pivoting tools exploit. The art is choosing the right first move based on what you already hold.
The diagram below shows the canonical pivot chain. Read it as a set of options rather than a fixed sequence: you enter wherever your starting identifier sits, and you exit when you have enough independent signals to be confident, not when you have simply found a single profile.
The reason this matters more than any single tool is that no individual source is complete or current. A username scanner will miss platforms that block bots, a reverse-email tool will miss someone who used a different address to sign up, and a face engine will miss anyone whose photos are private. By pivoting, you triangulate: each method covers the gaps of the others, and agreement across independent methods is what turns a guess into a finding. Throughout the rest of this guide, treat each category of tool as one stage in this chain rather than a standalone answer.
A concrete example makes the chain tangible. Suppose you have only a note that a candidate is a backend engineer who goes by devkadvya somewhere online. Running that handle through a username scanner returns a GitHub account, a Stack Overflow profile, and a personal site. The GitHub bio links to an X account under a slightly different handle, which a second scan confirms, and the personal site exposes a contact email. A reverse-email lookup then ties that address back to the same GitHub account, closing the loop. At that point four independent sources (handle reuse, a bio cross-link, a shared email, and consistent project history) all point to one person, and the identification is HIGH confidence. No single tool produced that result; the pivots did, and each one both widened coverage and tightened certainty.
The discipline that separates professionals from hobbyists is knowing when to stop. Once you have located the person and confirmed it with two or more independent signals, additional digging usually adds risk without adding value, and in regulated contexts (hiring, lending, housing) it can cross from sourcing into territory governed by law. Define the question before you start, collect only what answers it, and document each source and timestamp as you go.
3. People-Search Engines and Identity Aggregators
People-search engines are the most accessible entry point because they are built for non-technical users: you type in what you know and they return a consolidated profile. They divide cleanly into three tiers. Free aggregators like IDCrawl, TruePeopleSearch, and Social Searcher give you a fast first pass. Paid consumer subscriptions like Spokeo, BeenVerified, Intelius, and Instant Checkmate add depth and contact data. And enterprise identity-graph APIs like Pipl serve investigators and fraud teams at scale.
For finding social profiles specifically, the cleanest free move in 2026 is a username search. IDCrawl's username tool checks a handle across 100+ platforms including Instagram, TikTok, X, Facebook, YouTube, Snapchat, and LinkedIn, with no signup, drawing on 50+ data sources and over 10 million monthly searches - IDCrawl. TruePeopleSearch remains genuinely free with no paywall, aggregating US public records (property, voter registration, court, and utility filings) into a single view - Nubela. These cost nothing and are the right starting point before you spend a cent.
The paid consumer tier is where the value and the traps both live. Pricing clusters tightly, and the cheap "trial" hooks almost always auto-renew, so read the terms before you click. The table below reflects current verified pricing, but treat the trial figures as gateways to a recurring charge rather than one-off purchases.
| Tool | Entry / Trial | Ongoing Price | What It Adds |
|---|---|---|---|
| Spokeo | $0.95 / 7 days | $22.95/mo (1-mo) or $17.95/mo (3-mo) | Username search across 120+ sites, reverse email/phone |
| BeenVerified | $1 trial | $36.89/mo (1-mo) or $23.98/mo (3-mo), 100 reports/mo | Email + username lookup, dark-web scan |
| Intelius | $0.95 / 5-7 days | $21.13/mo (billed every 2 months) | Unlimited people/phone/address reports |
| Instant Checkmate | 5-day trial | $35.47 / 30 days | Background-style person and location reports |
Spokeo's $0.95-then-$22.95 structure and BeenVerified's 100-report monthly cap are both verified against current 2026 reviews - Top10. The recurring theme in user complaints across all four is billing: auto-renewal accounts for a large share of formal grievances, so set a calendar reminder to cancel if you only need one lookup. None of these services is FCRA-compliant, which has direct consequences covered in section 12.
Accuracy is the caveat that defines this whole tier. A bare name search is close to useless for definitive identification because common names collapse multiple people into one record or split one person across several. Independent 2026 testing of Spokeo, which pulls from over 12 billion public records, found it identified roughly 85% of phone numbers correctly while still surfacing outdated addresses and incorrect relatives - Digital Safety Squad. That 85% is good for a consumer tool and nowhere near good enough to act on without corroboration. The lesson is to use these engines to generate leads, then confirm with an independent method before you treat any single result as fact.
It helps to understand why accuracy varies so much, because the mechanism explains the failures. Identity resolution uses two kinds of matching. Deterministic matching links records only when a unique key (an exact email or phone) agrees, which is precise but misses anyone whose identifiers differ slightly. Probabilistic matching links records by weighing many fuzzy signals (similar names, overlapping addresses, shared relatives) and returns a confidence score rather than a yes-or-no answer. The probabilistic approach can lift match coverage from roughly 20 to 30% of records to 80 to 95%, but it forces a threshold choice that trades false positives against false negatives - Treasure Data. This is the common-name problem in technical form: set the threshold loose and two different people named Michael Johnson merge into one record, set it tight and one person splits into three. When a tool shows you a confidence score, it is exposing exactly this dial, and your job is to distrust everything below the top of the scale.
At the top of this category sits Pipl, which is a different animal. It is not a consumer subscription but a Search API that returns a consolidated identity from a fragment (a name plus city, an email, a phone, or a social URL), billed at roughly $0.10 per matched query with a default $1,000 monthly cap and match-only billing - SaaSworthy. Through its Maltego connector, Pipl exposes an index of over 3 billion cross-referenced online identities, which is why investigators, journalists, and trust-and-safety teams rely on it rather than the consumer tools - Maltego. For most readers Pipl is overkill, but it sets the ceiling for what identity resolution can do when accuracy and scale both matter.
If you prefer to watch the workflow before trying it, the walkthrough below demonstrates a people-search engine in action, pulling a person's accounts and public footprint from a name or username.
Finding social media accounts with a people-search engine
4. Reverse Image and Face Search
When you have a photo but no name, facial recognition is the most powerful tool available, and also the most legally fraught. It is essential to understand the distinction that trips up most beginners: classic reverse image search (Google Lens, TinEye) only finds the exact same image file republished elsewhere, while dedicated facial-recognition engines (PimEyes, FaceCheck.ID, Lenso.ai, Search4Faces) match a face across different photos. To find an unknown person's profiles from a single photo, you need the latter, and the former will repeatedly let you down.
The two leaders, PimEyes and FaceCheck.ID, take opposite approaches to the same problem. PimEyes indexes the open web most comprehensively, cited at roughly 3 billion images, and is the OSINT favorite for mapping where a face appears across news, blogs, and stock photography. Crucially, it deliberately does not crawl most social platforms directly, so it surfaces web pages that you then pivot from, rather than the profile itself. Its paid tiers run from Open Plus at about $29.99/month to Advanced at about $299.99/month, with the free tier showing only blurred thumbnails and a match count - Protevio. The screenshot below shows the upload interface where a search begins.
FaceCheck.ID is the stronger tool when your goal is the social profile itself rather than a web mention. It searches social media, news, video sites, and scammer and mugshot datasets, then links directly to the page where the face appears. In independent 2026 testing it outperformed PimEyes on real-world matches (scoring 79 out of 80 across 16 tests versus PimEyes at 57), and it has moved to a credit-pack model rather than a subscription, with packages from $6 (Just a Peek) to $597 (Professional) - Software Finder. The animated demo below shows the search-to-results flow.

What makes FaceCheck.ID especially usable is that it tells you how confident it is. It reports matches on a confidence scale (90-100 Certain, 83-89 Confident, 70-82 Uncertain, 50-69 Weak) and explicitly warns users never to rely on a face search alone because many unrelated people look alike - FaceCheck.ID. That warning is the single most important sentence in this section. A "Certain" match is a strong lead, not a conviction, and the tool's own makers are telling you so.
The other engines fill specific gaps. Lenso.ai is the developer-friendly option, with documented Face Search and Reverse Image Search APIs and tiers from $15.99/month (Starter) to $2,800/month (Developer) for 5,000 API calls - Lenso.ai. Search4Faces is free and specializes in Russian and Eastern European platforms, with a VKontakte database cited at exactly 1,113,850,873 faces, and it is listed in Bellingcat's investigation toolkit - Search4Faces. Meanwhile, Google Lens intentionally blocks face-based people search for private individuals (it shows a "Results for people are limited" message and recognizes only celebrities), and TinEye has no facial recognition at all. Knowing which tools refuse the job saves you from wasting time on them.
In practice, the strongest face workflow chains all three tool types rather than betting on one. Start with FaceCheck.ID to get a direct social-profile hit, run the same photo through PimEyes to catch open-web appearances (news, conference pages, stock photography) that FaceCheck misses, and drop the image into Google Lens or TinEye to find the exact-file origin and any reuse. Each engine indexes a different slice of the visual web, so a face that returns nothing on one will often surface on another, and a catfish photo that has been reused will betray itself through TinEye's provenance trail. When two independent engines return the same person on different source pages, that agreement is a far stronger signal than any single engine's confidence score, and it is the face-search equivalent of the pivot chain in section 2.
A word on accuracy, because it is conditional and widely misunderstood. The best algorithms in NIST's benchmark hit error rates near 0.07% under controlled conditions, with NEC ranking most accurate in a 1:N identification test on still images of 12 million people - NEC. Consumer face search degrades far below that lab number with poor lighting, oblique angles, masks, makeup, aging, or low resolution. Every one of these tools produces false positives, so a single face match is the beginning of verification, never the end of it. Section 11 covers why acting on an unverified match has put innocent people in jail.
The legal line here is the hardest in the entire field. The EU AI Act prohibits building or expanding facial-recognition databases through untargeted scraping of internet or CCTV images, a rule that took effect in February 2025 - EU AI Act, Article 5. That single provision is why Clearview-style mass scraping is effectively illegal in Europe and why PimEyes pulled out of Illinois. If your subjects or you are in the EU or Illinois, treat face search of strangers as off-limits and revisit section 12 before doing anything.
5. Username and Email OSINT Tools (Free and Open Source)
For anyone willing to run a command, the free open-source tools are the most powerful per dollar in this entire guide, because they cost nothing and cover more platforms than most paid services. Two engines dominate username search in 2026. Maigret checks a handle across more than 3,000 sites (its default run covers the top 500 by traffic, catching the vast majority of likely hits in seconds), parses profile metadata, recursively searches newly discovered usernames, and exports HTML, PDF, JSON, and CSV reports. Sherlock is the simpler classic, hunting a username across 400+ networks and printing found URLs.
Both install in a single command and need no API keys, which is why they are the standard sourcing primitives of 2026. Maigret has broadly overtaken Sherlock on coverage and false-positive handling, but Sherlock remains the lightweight first pass and ships pre-installed on Kali Linux. A typical session looks like this:
pipx install sherlock-project # or: pip install sherlock-project
sherlock johndoe # prints every found profile URL
pip install maigret # the deeper alternative
maigret johndoe --html # full dossier with a report file
Sherlock's terminal output makes the result format obvious: each discovered account prints as a line with the platform and a direct link, ready to open and verify.
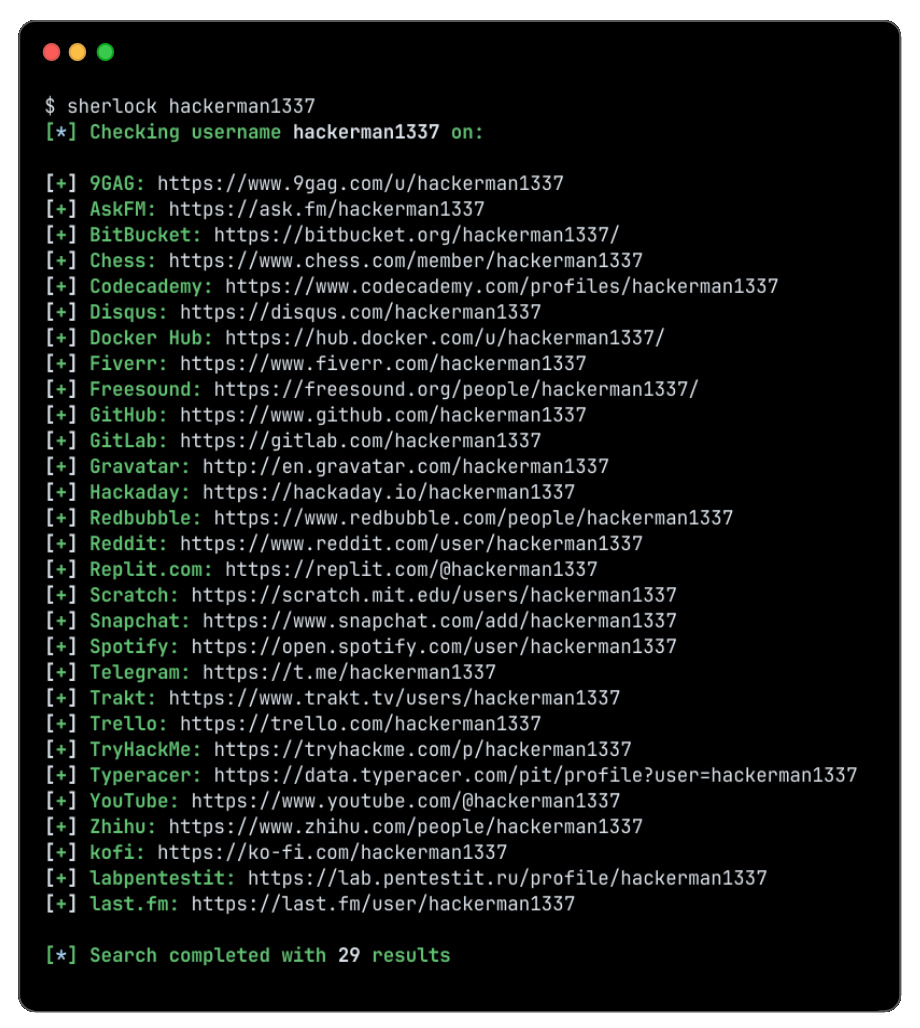
Reading the output is a skill in itself, because breadth comes at the cost of noise. A wide scan returns some false positives where a site reports success for any input, and some false negatives where bot protection silently blocks the check. The disciplined approach is to treat every hit as a candidate, open the ones that matter, and confirm the profile actually belongs to your subject rather than to someone who registered the same handle first. Maigret's recursive mode helps here: when it finds a new username or numeric ID on one profile, it searches that too, which often surfaces the accounts a person tried to keep separate from their main identity. Export the run to HTML or JSON so you have a timestamped record of what you found and where, which matters for both verification and legal defensibility later.
Underpinning much of this ecosystem is WhatsMyName, a community-maintained dataset of 700+ site definitions that powers Blackbird, Naminter, Recon-ng, Maltego, and SpiderFoot, and runs as a free no-install web app for non-technical users. If you learn only one dataset, learn this one, because it is the backbone the others share. Newer entrants build on it: Naminter covers 730+ sites and uses browser-impersonation techniques to beat the Cloudflare and bot-detection blocks that increasingly trip up older scanners, while Blackbird searches both usernames and emails across 600+ sites and adds free AI profiling.
Email-to-account discovery is the other half of this category, and it is led by two tools. Holehe checks whether an email is registered on 120+ sites by silently probing password-reset endpoints, without ever notifying the target. Epieos is the hosted, non-technical equivalent: a web app that maps an email or phone across 140+ services, surfaces the Google account name and photo behind a Gmail address, and cross-references breach data, with a free tier and a paid plan around 29.99 euros/month for full modules - Epieos. For Google accounts specifically, GHunt extracts display name, profile photo, public Maps reviews, and shared Drive files, though it requires you to supply your own Google authentication cookies.
The 2026 reality check is that these tools break at the edges, and you must plan for it. The main failure mode is not shutdowns but API lockdowns: Holehe's X and Instagram modules broke when those platforms hardened their reset endpoints, while the rest of its catalog still works - Holehe. Instagram-specific tools like Osintgram and Toutatis are especially fragile and risky because they require logged-in session cookies that can get your account banned, so treat them as burner-account tools only. The practical takeaway is to always assume a fraction of any scanner's sites are stale, and to read an absence of results as inconclusive rather than as proof the person is not there.
The most interesting 2026 development is that these primitives are becoming AI-callable. Maigret added an --ai summary mode and ships a community MCP server, so an assistant like Claude can run a username search directly and reason over the structured output - Maigret. That bridge between deterministic OSINT tools and language models is the foundation of the agentic approach covered in section 7, and it matters because it lets a model build on real tool output instead of inventing results.
6. Commercial OSINT and Link-Analysis Platforms
When the job requires mapping a network rather than finding a single account, commercial link-analysis platforms are the professional standard. The clear market leader is Maltego, which Frost and Sullivan named the 2025 Global Product Leader in OSINT, used by 2,000+ government bodies and 4,000+ companies across 120+ countries. Maltego maps relationships between entities (people, profiles, emails, domains) using "Transforms" that query 120+ data partners, turning scattered data points into a single visual graph. Its pricing is unusually transparent for this tier: a free Basic plan, then 3,000 euros/year (Entry) and 7,500 euros/year (Professional) before Enterprise - Maltego.
The value of the graph is best seen, not described. In the screenshot below, a single person entity branches out to connected industry, location, phone, and social-profile data produced by a single Transform, which is how an analyst turns one identifier into a web of corroborating links.

The platforms split into two pricing worlds, and the divide tells you who they are built for. Self-serve, transparent vendors include Maltego, OSINT Industries (a reverse-lookup tool from 19 pounds/month that turns an email, phone, or username into linked accounts), Intelligence X (a leak and dark-web archive from 2,500 euros/year), and Lampyre (a low-cost Maltego alternative around $32/month). The heavyweight government and law-enforcement vendors, by contrast, are enterprise-only and quote on request: Social Links, Skopenow, ShadowDragon, and PenLink (formerly Cobwebs).
For finding social profiles at scale, a few of these stand out. ShadowDragon's SocialNet queries 200+ platforms at once and, critically, retains historical snapshots even after a target deletes or renames accounts - ShadowDragon. Social Links runs SL Professional as a Maltego add-on and a standalone SL Crimewall platform, both extracting and visualizing data across 500+ open sources including social media, messengers, and the dark web, used by law enforcement in 80+ countries. The Crimewall interface below shows the investigation workspace these teams use.
.webp)
The defining 2026 trend across this tier is agentic AI. PenLink's CoAnalyst moved to agentic AI that autonomously executes multi-step investigative workflows and auto-generates summary reports, Maltego added an AI Assistant for person-of-interest investigations plus a dedicated social-media profile view that aggregates a single profile into one card, and Social Links markets AI-driven link analysis with biometric and image analysis across its sources - Social Links. The market is also consolidating: PenLink acquired Cobwebs in 2023, and Intel 471 acquired SpiderFoot in 2022, so the open-source SpiderFoot remains free on GitHub while its cloud version folds into a larger threat-intelligence suite.
For most readers, these platforms are more than the task requires, but they matter for two reasons. First, they define the upper bound of what is technically possible, which helps you calibrate what a free tool can and cannot do. Second, the access model is instructive: the heaviest tools gate their power behind vetting and confidentiality precisely because the capability is dangerous in the wrong hands. Skopenow vets every paid account, and Social Links does not name its clients. That gatekeeping is itself a signal about the ethical weight of network-scale profile discovery.
7. AI Agents and Autonomous Profile Discovery
The most important shift of 2026 is the move from chatbots to agents. A year ago, finding someone with AI meant asking a model and getting a plausible, often wrong, answer. Today, ChatGPT agent, Gemini Deep Research, Perplexity, and Claude all chain search, browse, and reasoning across many sources autonomously, then return a cited report. "Find this person's social profiles" has become a natural-language task you can hand to an agent that will plan the investigation, open candidate profiles, and reason about which ones match. This is genuinely new, and it is genuinely risky, in roughly equal measure.
The major launches landed in the last twelve months. OpenAI's ChatGPT agent combines deep research with a real browser, and as of February 2026 its deep research can connect to any MCP server and be restricted to trusted sites - ChatGPT. Google shipped Gemini Deep Research Max on April 21, 2026, running on Gemini 3.1 Pro with MCP support and collaborative plan review. Perplexity's Comet browser went fully free on March 18, 2026, and Claude's web search tool adds always-on citations at $10 per 1,000 searches plus dynamic filtering. Pricing for the consumer agents is modest: ChatGPT Plus and Perplexity Pro both run $20/month, putting agentic research within reach of any professional.
The connective tissue underneath all of this is the Model Context Protocol (MCP), which lets a model call real tools instead of guessing. This is where agentic OSINT gets genuinely reliable. Purpose-built agents like the open-source OpenOSINT describe a target in natural language and let a Claude-powered agent decide which of nine real tools to run (Sherlock across 300+ platforms, Holehe, HaveIBeenPwned, WHOIS, and more), chaining them on findings and outputting a structured report. Its key design principle is that the model "never infers or synthesizes what a tool would return; it only ever sees real output," which is what makes it architecturally resistant to fabrication. The OWASP Social OSINT Agent takes the same API-only approach across X, Reddit, GitHub, Bluesky, and Mastodon.
For developers and recruiters who want programmatic discovery, specialized search APIs are cheap and built for exactly this. Exa offers a people-category index over 1 billion profiles with metadata, at $7 per 1,000 searches with 20,000 free monthly, and can restrict results to LinkedIn in a single call - Exa. Tavily, a search-and-extract API for grounding agents, was acquired by Nebius for roughly $275 million in February 2026, a signal of how valuable agent-grade search has become - Tavily. These APIs return real indexed URLs, which keeps hallucination on existence low, even though semantic matching can still surface the wrong person with the same name.
That brings us to the dominant risk, which you must internalize before using any of these tools for people-finding: hallucination. Studies in 2025 and 2026 found citation-fabrication rates ranging from 29% to 86% across conversation turns even on a fixed topic, with frontier models scoring only 4 to 18% on citation-attribution benchmarks - arXiv. Agents will confidently assert that a profile belongs to your target, complete with a working link to an unrelated page. Never trust an unverified "this is their profile" claim from an agent. The defensible pattern is the "hallucination insurance" stack: one agent gathers, a second adversarially challenges the findings, every claim is grounded to a clickable source, and a human owns final verification - My Weird Prompts.
Structuring the request well is what makes a general agent usable for this. A defensible prompt scopes the task narrowly ("find the public LinkedIn, GitHub, and X profiles for this specific person at this company"), constrains the sources (restrict deep research to trusted domains, which ChatGPT and Claude both now support), and demands a citation for every claim with an explicit instruction to mark anything uncertain as unverified rather than to guess. Then you do the part the agent cannot: open each cited link and confirm it. The agents that perform best for people-finding are the ones wired to real tools, like OpenOSINT calling Sherlock and Holehe, precisely because the model reasons over actual output instead of its own memory. A general chatbot asked to "find someone's socials" with no tools attached is the worst case, because it will produce fluent, well-formatted, and frequently fictional results that are hard to distinguish from real ones.
Demand for this is not hypothetical. Korn Ferry's 2026 survey of more than 1,670 talent leaders found 84% plan to use AI in recruiting and 52% plan to add autonomous AI agents to their teams - Korn Ferry. Agentic sourcing is moving from experiment to standard workflow within a single year, which is exactly why the verification discipline in section 10 is becoming a core professional skill rather than a nice-to-have. The video below shows an autonomous sourcing agent finding and engaging people at enterprise scale, which is the clearest illustration of where this is heading.
AI Sourcing Agents in the Enterprise: Live demo
8. Cross-Platform Sourcing for Recruiters and Sales
For recruiting and sales, the workflow has a specific shape: partial-info-to-profile. You start with a name, a company, or an email, and you need the person's LinkedIn and GitHub plus a verified work email and mobile number. The tools in this category differ mainly along three axes: database size, real-world accuracy, and how aggressively they meter credits. Understanding those trade-offs matters more than any single vendor's marketing, because the gap between claimed and actual accuracy is large.
Database size and accuracy trade off against each other. Large-database tools maximize coverage: HeroHunt.ai searches 1 billion+ profiles across LinkedIn, GitHub, and Stack Overflow, People Data Labs sits around 1.5 to 3 billion records, and ContactOut covers 300 million+. But independent tests repeatedly show real email match rates of 40 to 85%, well below the 95 to 99% that vendors market. One third-party test of ContactOut returned just 42 valid emails out of 100 contacts with a 7% bounce rate, against its advertised 99% accuracy - SyncGTM. The practical rule is to verify any list before bulk outreach, no matter what the vendor claims.
The real cost driver is credit metering, not the sticker price, and phone reveals are where it bites. The table below shows the 2026 pricing bands; note how the structure, not just the headline number, determines what you actually pay.
| Tool | Entry Price | Credit Model | Best For |
|---|---|---|---|
| SignalHire | $57-69/mo | 1 credit only when data is returned | Multi-platform contact discovery, no per-seat fee |
| Apollo.io | $49/user/mo | Emails unlimited (fair use), mobiles ~8x cost | Database plus outreach in one seat |
| Lusha | $49.90/mo | 1 credit/email, 10 credits/phone | Direct-dial phone numbers, CRM sync |
| ContactOut | $49/mo annual | Fair-use caps (~2,000 emails, 1,000 phones) | LinkedIn-native sourcing |
| Clay | $185/mo | Waterfall across many providers | Highest match rate via multi-provider enrichment |
The pattern across Apollo, Lusha, Clay, and Wiza is consistent: phone and mobile reveals cost far more than emails (Lusha charges 1 credit per email versus 10 per phone), and most plans do not roll credits over month to month - Lusha. Clay sits at the top because it runs "waterfall" enrichment across many providers to maximize match rates, and its March 2026 repricing cut data costs 50 to 90% while eliminating failed-lookup charges, which materially changed total cost of ownership - Clay. For budget-conscious teams, Nymeria and post-March-2026 Clay both follow a no-charge-for-failed-lookups model worth seeking out.
A worked example shows why the credit model dwarfs the sticker price. Imagine a recruiter who needs 500 verified mobile numbers a month. On Lusha, where a phone costs 10 credits versus 1 for an email, those 500 phones consume 5,000 credits, far beyond the roughly 600 credits in the $69.90 Pro plan, which pushes the real cost into a much higher tier or per-credit overages. On Apollo, mobile credits run roughly eight times the cost of an email and stay tightly capped even on upper plans, so heavy phone use forces an Organization seat. The same 500 emails, by contrast, are effectively unlimited under fair use on most paid plans. The lesson is to size your plan to the expensive identifier you actually need, usually phone or mobile, rather than to the advertised headline price, and to favor tools that charge only when they return real data.
The 2026 differentiator is the AI agent layer sitting on top of the database. Rather than returning a list for you to work through, these tools find, screen, and contact people on their own. HeroHunt.ai's AI Recruiter searches the billion-profile index from a one-line description, screens candidates with a language model, finds verified emails, and auto-sends personalized outreach, positioning it as one option among several agentic platforms alongside Juicebox, SeekOut, and hireEZ - HeroHunt.ai. A separate sub-category, website-visitor identification, resolves anonymous US web traffic to person-level LinkedIn profiles: RB2B does this with real-time Slack alerts, though coverage is US-only and typically identifies just 5 to 20% of traffic.
For recruiters specifically, the enterprise platforms are worth knowing even if their pricing puts them out of reach for individuals. SeekOut searches 1 billion+ profiles with diversity filters at roughly $20,000/year median, and hireEZ indexes 750 million+ profiles across 45+ platforms at a lower $13,000 median - Juicebox. The natural-language layer is now table stakes across all of them, which is the clearest sign that the Boolean-search era is ending. The demo below shows one such tool turning a plain-English description into a candidate set, which is the experience most of these platforms now offer.
AI sourcing tool live demo: natural-language candidate search
9. Platform by Platform: LinkedIn to Bluesky
Every platform behaves differently, and the biggest change reshaping profile-finding in 2026 is API lockdowns. X moved new developers to pay-per-use on February 6, 2026, with no free tier, Reddit charges commercial users around $0.24 per 1,000 calls, and Instagram's Graph API allows roughly 200 calls per hour behind mandatory business verification - PostProxy. The practical consequence is that bulk API access is effectively closed to non-enterprise users, so professionals lean on native platform search, Google dorks, and AI aggregators instead. The methods below are organized by what still works for each platform.
The universal fallback across every platform is Google site: dorking, and it remains the most reliable free method in 2026. Restricting a search to one platform (for example, site:linkedin.com/in "product manager" "Berlin", or site:instagram.com inurl:username) surfaces indexed public profiles without logging in. For LinkedIn specifically, X-ray search plus Boolean operators is still a core recruiter skill, used to reach profiles outside LinkedIn's own commercial-use search limits, even though LinkedIn's robots.txt discourages automated crawling. DuckDuckGo and Yandex index different slices of the web and will surface results Google misses, so running the same dork across multiple engines widens coverage.
A concrete example shows the precision these operators buy. To find a specific person's Instagram when native search fails, a query like site:instagram.com "Full Name" often surfaces the profile or a tagged post that names them, and adding a location or employer term narrows it further. To catch a LinkedIn profile that LinkedIn's own search hides behind commercial limits, a query like "name@company.com" site:linkedin.com can pull it up when the email appears anywhere on the public profile. Google supports around 25 operators in 2026, but a handful carry the weight: site:, intitle:, inurl:, intext:, quoted exact phrases, the OR combiner, the minus sign to exclude noise, and before: and after: to bound results by date. Chaining several site: queries with OR lets you sweep multiple platforms in a single search rather than repeating the same work five times.
Native AI has also changed in-platform sourcing. LinkedIn's Hiring Assistant lets you describe candidates in plain English instead of writing Boolean, and per LinkedIn's January 2026 data it claims an 81% reduction in profile reviews, a 66% lift in InMail acceptance, and about 1.5 hours saved per role - LinkedIn. LinkedIn Recruiter Lite runs $170/month and Sales Navigator Core $119.99/month, the practical entry points for serious in-platform work. Beyond LinkedIn, AI people-search aggregators (Juicebox, HeroHunt, SeekOut, hireEZ) now turn a natural-language description, name, or username into cross-platform profile sets in seconds, blending LinkedIn, X, GitHub, and the open web.
The platform-specific realities are worth knowing before you waste effort:
- LinkedIn: native search plus X-ray dorks; the richest professional data but the most aggressive anti-automation.
- X (Twitter): free native advanced search (
from:,since:,until:) is the practical route now that the API is pay-per-use. - GitHub: operators like
language:,location:, andfollowers:find engineers, but most hide their email, so pair with username correlation. - Bluesky: the outlier, with a free AT Protocol firehose and powerful native operators, making it the most open major platform.
- Facebook / Instagram / Threads: Graph Search has been gone since 2019, so finding profiles relies on email/phone reverse lookup, mutual-connection analysis, and reverse image search.
The standout among these is Bluesky, whose AT Protocol firehose is free with no per-call fee and whose native search supports from:, mentions:, since:, until:, and domain: operators - Blotato. In a year defined by platforms closing their doors, Bluesky is the rare one opening them, which makes it disproportionately useful for legitimate research. At the opposite end, Facebook Graph Search was deprecated in June 2019, and Meta now routes serious research through its access-gated Content Library, restricted to vetted academic and non-profit researchers.
The cross-cutting tactic that ties all platforms together is username correlation, which is why section 5's tools matter so much here. Because people reuse handles, running one username through WhatsMyName (732 sites), Maigret (3,000+ sites), or Sherlock instantly checks hundreds of platforms at once, including the niche ones you would never search by hand. Reverse face search adds a parallel bridge: PimEyes finds open-web appearances but deliberately excludes social platforms, so pair it with reverse image search on Google or TinEye and with username tools to get from a face to an actual profile. No single platform method is sufficient, which returns us to the pivot chain as the organizing principle.
10. Verification: Turning a Match Into a Confirmed Identity
Finding a candidate profile is the easy part. Confirming it belongs to the right person is the part that separates competent work from costly mistakes, and it is where most automated workflows quietly fail. The core principle is that handle reuse is not proof of identity. The same username can belong to different people, an AI agent can assert a wrong match with total confidence, and a face engine can surface a stranger who merely looks similar. Verification is the discipline of refusing to believe any of them until independent signals agree.
The practical method is confidence scoring against independent signals. Treat a match as HIGH confidence only when three or more independent signals agree, MEDIUM at two, and LOW at one or anything circumstantial, and act only on HIGH-confidence matches. The strongest individual signals are a reverse-image-matched avatar (the same face on two profiles), mutual-connection or follower overlap, a consistent bio and cross-links between accounts, and matching account-creation timing. A single shared first name and city is not a signal; a reused rare handle plus a matching avatar plus a cross-link in a bio is. The difference is whether the signals are independent or just restatements of the same weak fact.
Seasoned investigators lean on structured frameworks to avoid fooling themselves, because the natural tendency is to look for reasons a match is right rather than reasons it is wrong. Two are worth adopting:
- SIFT: Stop, Investigate the source, Find better coverage, and Trace claims to the original.
- R2C2: weigh Relevance, Reliability, Credibility, and Corroboration before accepting a finding.
Both frameworks share a single insight that is easy to state and hard to practice: require two or more independent sources, and actively hunt for the disconfirming evidence. Lock identity onto a unique pivot (a middle name, a prior address, a distinctive cross-platform handle) rather than a common one, and when you cannot find a second independent confirmation, record the finding as unconfirmed rather than promoting it. This is also where the legal stakes concentrate, because acting on a misidentification in hiring, lending, or safety contexts is exactly the harm that the laws in section 12 exist to prevent.
Walking through a real disambiguation shows the discipline in action. Say a face search returns a "Confident" match linking a photo to an Instagram account, and a username scan finds the same handle on X and TikTok. That looks like three signals, but they may not be independent. If the handle is distinctive and the X bio links back to the same Instagram, the accounts genuinely corroborate each other and you reach HIGH confidence. If instead the handle is generic (a common first name plus a number) and nothing cross-links, you have one weak signal repeated three times, which is LOW confidence no matter how many platforms display it. The test is never how many profiles you found; it is whether the signals are independent and whether you actively searched for the version of events in which the match is wrong. Investigators who skip that second step are the ones who confidently misidentify people.
Breach-data lookups are a legitimate corroboration tool when used carefully, because they surface old usernames and emails that tie identities together. Have I Been Pwned offers free browser email search and an API from $4.39/month, and it can confirm that an email and an alias appeared in the same breach, strengthening a link - Have I Been Pwned. The hard ethical line is that breach data is for correlating identifiers, never for accessing accounts; using leaked passwords to log in is a crime. Verification, done right, makes you slower and far more accurate, which is the correct trade in any context where being wrong about a person has consequences.
11. Accuracy, Limitations, and Failure Modes
Every tool in this guide fails in predictable ways, and knowing the failure modes is what keeps you from acting on a confident error. The first rule is that AI face search is a lead, never proof. Even top NIST-tested algorithms hold false positives near 0.3%, but at population scale that produces many similar-looking false matches, and consumer tools like PimEyes openly admit they return people who merely look similar. Worse, the errors are not evenly distributed: NIST's demographic testing found false-positive rates varying by up to a factor of 7,203 across groups, with women, children, the elderly, and Black individuals far more likely to be misidentified - NIST.
The consequences of ignoring this are not theoretical. Randal Reid spent six days in a Louisiana jail on a Clearview AI match with zero corroboration, later settling for $200,000 after phone records proved he was in another state - Biometric Update. At least 14 documented US wrongful arrests trace to facial recognition, including a woman jailed for six months and a man, Trevis Williams, arrested despite being eight inches taller and 70 pounds heavier than the actual suspect - ACLU. In every case the failure was the same: a match treated as evidence instead of a lead. The technology was not the villain so much as the decision to act on it without verification.
Language models fail differently but just as confidently. They fabricate names, profiles, and URLs at high rates, and making them "reason harder" can make it worse. A 2026 benchmark of deep-research agents scored their hallucination tendency on a scale where lower is better, and the spread across vendors is wide enough to matter when you choose a tool.
Deep-Research Agent Hallucination Score (Lower Is Better)
Even the best agents in that benchmark fabricate, and several showed restriction-neglect failure rates of 18 to 30%, ignoring the limits you set - arXiv. Broader testing of 13 models found citation-hallucination rates between 14% and 95%, with wholesale fabrications (invented profiles with working links to unrelated pages) the dominant pattern - SQ Magazine. The operational rule that follows is absolute: open and verify every URL an agent gives you, because a meaningful fraction of them point at the wrong person or nothing at all.
Two more failure modes round out the picture, and both cut against over-trusting a thin result. First, the platforms you search are increasingly polluted by AI-generated fake personas: LinkedIn proactively removes about 99.6% of fake accounts, yet the FTC still logged 60,000+ job-scam reports in the first half of 2025 with losses near $300 million, increasingly using AI faces and deepfake video - LinkedIn. The $25.6 million Arup deepfake video-call fraud showed that even live video is no longer proof of identity - CNN. Second, data decays: B2B contact data goes stale at roughly 22 to 30% per year, so a "found" profile or email can be wrong simply because it is out of date.
Finally, remember that absence of a profile means nothing. Around 7% of Americans were offline at the start of 2025, and people can deliberately stay off-grid or use photo-cloaking tools, so not finding someone is not evidence about them. The thread running through every failure mode is the same: tooling finds candidates, but only verification confirms them, and the cost of skipping verification scales with the stakes of the decision. Treat thin, single-source matches as hypotheses, and reserve your confidence for findings that survive a deliberate search for reasons they might be wrong.
12. Privacy, Legal, and Ethical Guardrails
The legal frame around finding people shifted meaningfully in the last two years, and operating inside it is not optional. Start with the foundational question of scraping public data, where the news is mixed. US courts have held that the Computer Fraud and Abuse Act does not bar access to public web pages (the Ninth Circuit in hiQ v. LinkedIn), and that platform Terms of Service do not bind a logged-out scraper (Meta v. Bright Data, January 2024) - Bright Data. But hiQ still paid a $500,000 judgment for breaching LinkedIn's User Agreement using fake accounts and accessing password-protected pages - Proskauer. The practical rule: public, logged-out data is defensible, but scraping behind logins, using fake accounts, or touching private data remains high-risk.
Facial-recognition search of strangers is the single most legally dangerous technique in this guide. The EU AI Act has banned, since February 2025, the untargeted scraping of facial images from the internet or CCTV to build face-recognition databases, with fines up to 35 million euros or 7% of global turnover - EU AI Act. Clearview AI is the cautionary tale that gives the rule teeth: a 30.5 million euro Dutch fine, over 100 million euros in cumulative EU penalties, and a US settlement handing claimants a 23% equity stake valued at $51.75 million, approved in March 2025 - Loevy & Loevy. If you operate in or your subject is in the EU, face search of strangers is effectively off the table.
In the United States, biometric law is a patchwork with sharp edges. Illinois BIPA makes it illegal to collect faceprints without prior written consent, with statutory damages of $1,000 to $5,000 per violation, which is why PimEyes and Clearview pulled out of Illinois - Privacy World. Only Illinois, Texas, and Washington have standalone biometric laws, but the enforcement is real: Texas secured a $1.4 billion settlement with Meta under its biometric statute. The clearest line for any reader doing professional work touching US residents is to avoid face-search of strangers entirely in Illinois and to treat biometric data as legally radioactive everywhere else.
For hiring specifically, the Fair Credit Reporting Act is the hard limit, and it catches more tools than people expect. If you use a third party (a people-search site, an AI background dossier, or a screening vendor) to evaluate a candidate, that report becomes a "consumer report" and triggers FCRA duties: standalone disclosure, written consent, and pre-adverse and adverse-action notices. CFPB Circular 2024-06, issued in October 2024, explicitly confirmed that AI background dossiers and algorithmic scores fall under the FCRA - CFPB. This is why nearly every consumer people-search tool prominently disclaims FCRA compliance, and why eligibility decisions must run through a licensed screening vendor like Checkr or Sterling - FTC.
A concrete scenario clarifies where the lines fall for everyday sourcing. A recruiter who finds a candidate's public LinkedIn and GitHub, notes their skills, and sends a personalized outreach message is on solid ground in both the US and the EU, provided that in the EU they document legitimate interest and notify the candidate that they hold their data. The same recruiter crosses a line the moment they run that candidate through a people-search site or AI dossier tool to inform a hiring decision, because that report is now a consumer report under the FCRA with full consent and disclosure duties. And they cross a different line if they reverse-image-search the candidate's face to dig up personal accounts, which adds biometric exposure for no legitimate hiring purpose. The deciding questions are always the same: is the data public and professionally relevant, do I have a lawful basis, and is this feeding an eligibility decision?
In the EU and UK, sourcing someone you did not hear from directly relies on legitimate interest as the GDPR legal basis, which requires a documented balancing assessment and an obligation to notify the person you are processing their data, typically within a month. You cannot silently export sourced contacts into a CRM and begin outreach without a lawful basis and notice. Regulators are also tightening data-broker rules: the FTC ordered Gravy Analytics and Venntel to stop selling sensitive location data in December 2024, part of a broader crackdown - FTC. The responsible-use baseline that keeps you defensible is consistent across jurisdictions: stick to public, professionally-relevant information, have a lawful basis and give notice, never make an eligibility decision without FCRA compliance, avoid face-search of strangers in the EU and Illinois, and never act on protected-class characteristics you happen to discover.
13. The Future: Agentic OSINT and Decentralized Identity
The clearest trend line for 2026 and beyond is the move from passive aggregation to agentic OSINT. Tools are shifting from search-and-list dashboards toward autonomous agents that plan multi-step investigations, reason across sources, and run multimodal searches that combine text, image, and geolocation. Image-to-location agents already return street-level coordinates from a single photo by analyzing architecture, signage, and terrain, which expands "find a profile" well beyond name and email lookups. Expect this agentic, multimodal framing to be the dominant product narrative through 2027.
Capital is validating the direction at scale. In roughly a two-week span in August 2025, IVIX raised a $60 million Series B for LLM-plus-graph OSINT and Ontic raised a $230 million Series C led by KKR to unify open-source and internal security data - Ontic. Earlier in 2025, Persona raised $200 million at a $2 billion valuation explicitly to build a "verified identity layer for an agentic AI world" - SiliconAngle. The investment thesis is consistent: as autonomous agents proliferate, both finding people and verifying them become core infrastructure rather than niche tooling.
The underlying market growth supports that thesis. The OSINT market's trajectory, shown below, captures the steepness: a near-tripling over five years as AI, rising cyber threats, and expanding digital footprints compound. The numbers will be revised, but the slope is the story.
OSINT Market Growth, 2025-2030 (USD Billions)
Regulation is the biggest swing factor through 2027, and it cuts both ways. The EU AI Act already bans untargeted facial scraping, but a May 2026 "digital omnibus" deal pushed high-risk system rules (including biometrics and employment uses) from August 2026 to December 2027, giving vendors more runway while signaling tighter rules ahead. The US remains a patchwork, but roughly 20 states now treat biometric data as "sensitive" under consumer-privacy laws, and the AI agents market itself is projected to grow from $7.84 billion in 2025 to $52.62 billion by 2030 - MarketsandMarkets. The direction of travel is more capability and more constraint at the same time, which rewards builders and users who design for compliance from the start.
The genuine wildcard is decentralized identity, which could reshape whether profiles can be resolved at scale at all. The market is small today, estimated around $5 billion in 2026, but forecast to grow at an extraordinary 70.8% compound rate as self-sovereign identity standards mature - GMInsights. If individuals gain real control over their identity data, the aggregation model that powers most of today's tools could erode, shifting the field from "find anyone" toward "request and verify with consent." That would be a healthier equilibrium than the current one, and it is the most important thing to watch over the next several years.
14. Putting It Together: Which Approach to Use When
The right tool depends entirely on what you start with and what you are allowed to do, so the decision framework is best organized around your starting identifier and your purpose. If you start with a username, begin free: run it through WhatsMyName or Maigret, then pivot to the profiles you find. If you start with an email, lead with a reverse-email lookup (Epieos or Holehe for free, OSINT Industries for a polished paid version). If you start with a photo, use FaceCheck.ID or PimEyes, but only where the law permits and only as a lead. If you start with just a name, expect noise, and use a people-search engine or an AI agent to narrow before you verify.
Match the tool tier to the stakes, not to the budget. For casual reconnecting or a quick check, free tools and a consumer subscription are plenty. For recruiting and sales at volume, a cross-platform sourcing platform with verified contact data earns its price, and the agentic layer (whether HeroHunt.ai, Juicebox, SeekOut, or a custom Exa-powered agent) is where the time savings concentrate. For investigations, fraud, and trust-and-safety work, the commercial graph platforms and identity-resolution APIs justify their cost through scale and historical coverage. The mistake is paying enterprise prices for a casual lookup, or trusting a free consumer tool with a decision that has real consequences.
Whatever tier you choose, three rules carry across all of them. Pivot, do not rely on one source, because every tool has gaps the others fill. Verify before you act, requiring two or more independent signals before you treat a match as confirmed, because the cost of a false match scales with the stakes. And know your legal lane: stay on public data, have a lawful basis and give notice under GDPR, route hiring decisions through an FCRA-compliant vendor, and avoid face-search of strangers in the EU and Illinois entirely. These are not bureaucratic afterthoughts; they are what separates defensible professional work from the kind that ends in a fine or a wrongful accusation.
The deeper takeaway is that AI has made finding people easy and made being right about them harder. The tools will keep getting more capable, more autonomous, and more convincing, which means the scarce skill is no longer discovery but judgment: choosing the right method, triangulating across sources, and refusing to believe a confident answer until independent evidence agrees. Whether you use a free command-line scanner, a billion-profile sourcing platform, or an autonomous agent, the workflow that produces trustworthy results is the same one this guide opened with: pivot, corroborate, verify, and stay within the lines. Master that, and the specific tool you pick becomes a detail rather than a risk.
This guide reflects the AI profile-discovery landscape as of June 2026. Tools, pricing, accuracy, and especially the legal and regulatory rules change frequently. Verify current details with each vendor and confirm your own legal obligations before searching, sourcing, or making any decision about a person.