



Machine Learning is one of today's most promising technologies. Especially in the last 10 years the interest in Machine Learning has been rapidly increasing. But what many people don't know, is that Machine Learning already came about in 1952 when scientists began experimenting with programming machines to remember their own previous actions.
What is Machine Learning (ML)?
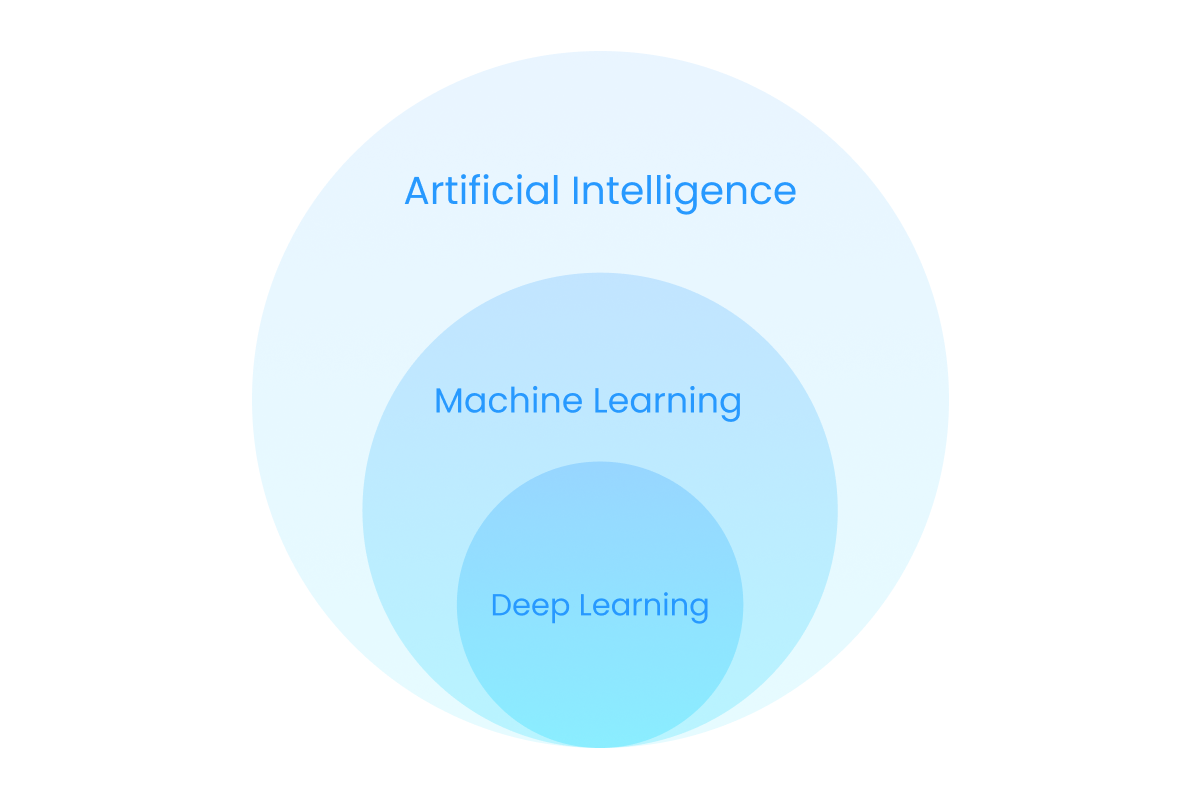
Machine learning (ML) is an application of artificial intelligence (AI) that has the ability to improve itself from experience automatically without being explicitly programmed. It does so by learning from data — text, numbers or for example photos.
Examples of Machine Learning that most of us have experienced in real life are:
- Recommendation engines (like Netflix and YouTube suggestions)
- Image analysis (like Google Photos’ face recognition)
- Chatbots (like customer service chatbots)
- Semi self-driving cars (like some of Tesla’s cars)
- Medical diagnostics (like medical image recognition and other medical information analysis)
There are three main types of machine learning algorithms that have their own way of learning:
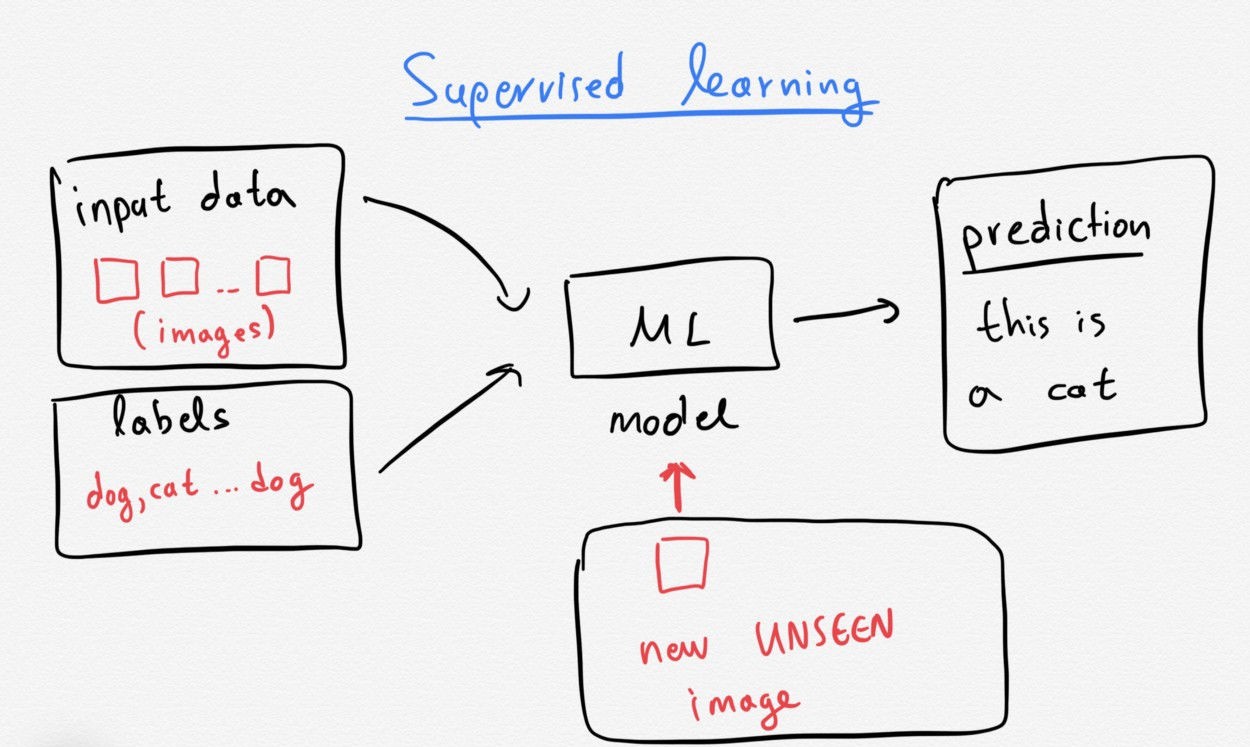
Supervised learning: Models that are trained with labelled data sets on which the model learns. The input data can be for example pictures of cats and other things. The pictures are labelled by humans, some are cats and some are not cats. The machine learns to recognize patterns in pictures of cats and over time is able to recognize them on its own. Supervised machine learning is the most common type used today.
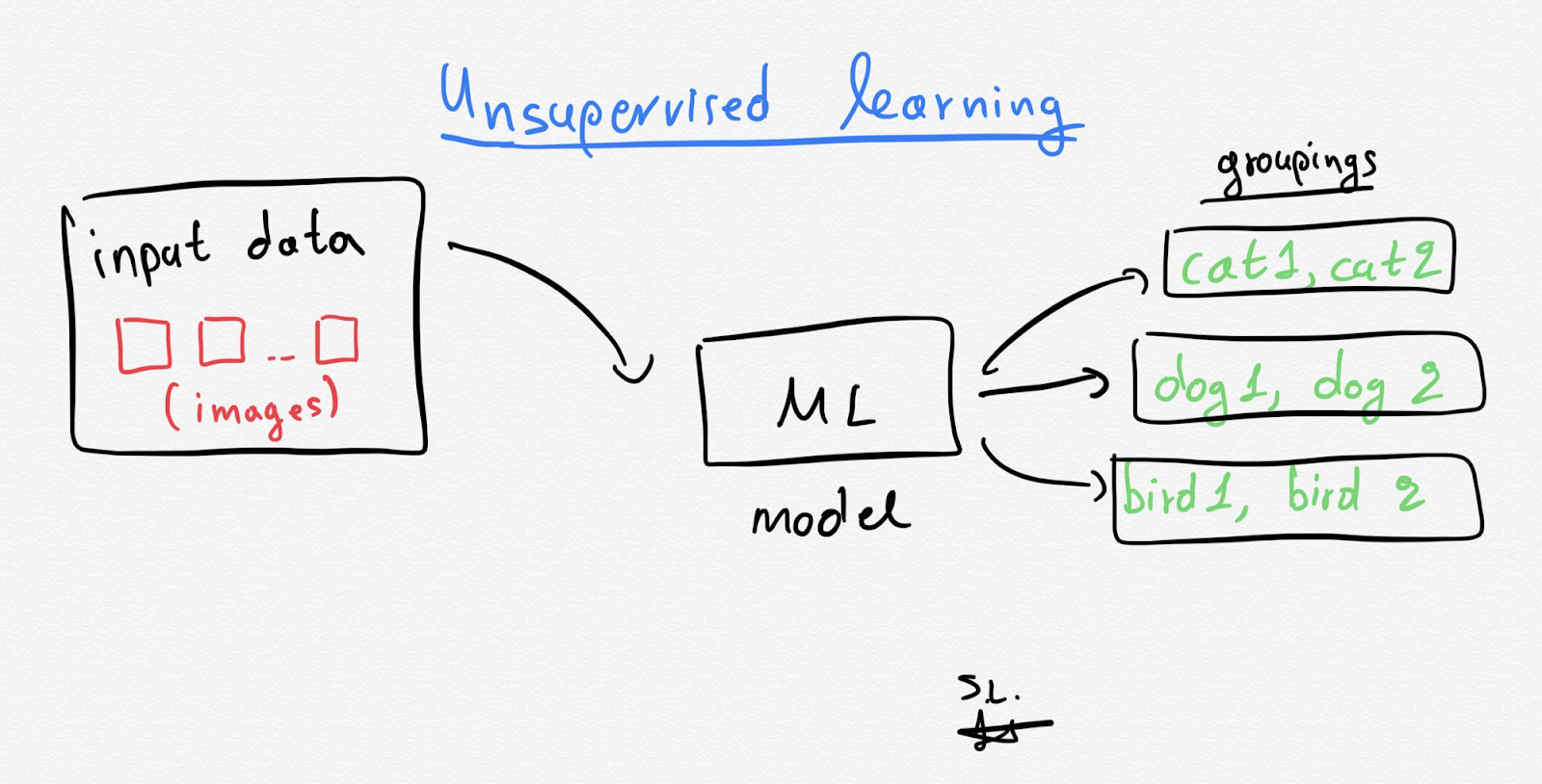
Unsupervised learning: Models that learn with unlabelled training data. The unsupervised program looks for patterns in the unlabelled data and can find patterns or trends that people aren’t explicitly looking for. Unsupervised learning is widely used to uncover groups within data (referred to as clustering) and to predict rules that describe data (referred to as association). An example is a Machine Learning model that starts to see patterns in certain types of customers of a webshop and categorizes them accordingly.
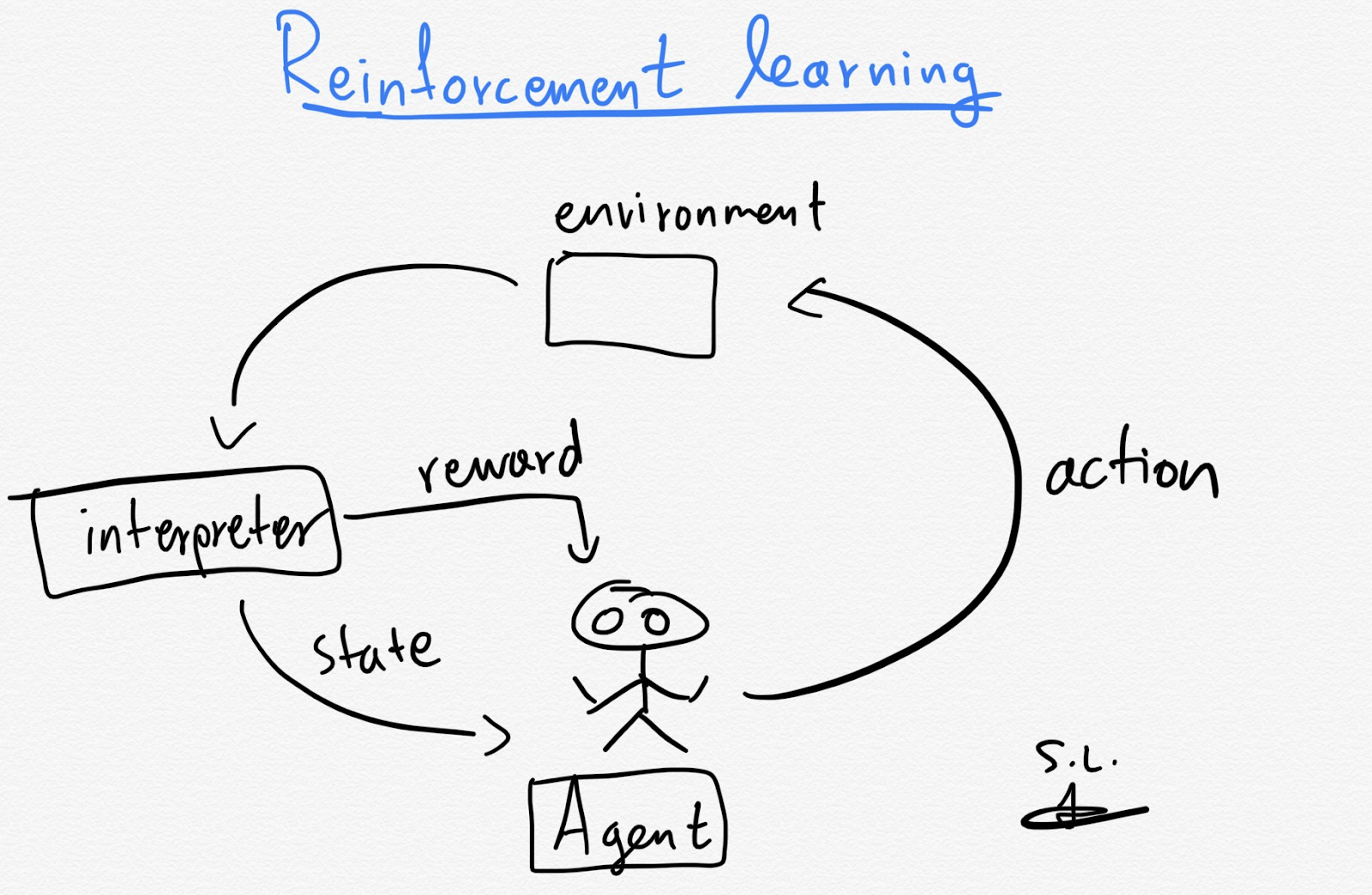
Reinforcement learning: Models that have been given a set of guidelines and, through trial and error, learn to take actions with the best possible outcome. In case the outcome of the machine’s action is desirable it is positively reinforced with rewards, if actions lead to undesirable outcomes it is sanctioned. An example is an autonomous vehicle that is told when it makes the right decisions and when it doesn’t.
Deep Learning is a subset of Machine Learning in which the intelligence of the system is made up of neural networks with many different layers. Deep Learning can process extensive amounts of data and determine the weight of connections in the network. In face recognition for example, some layers might be responsible for recognizing the shape of the nose and other layers look at the overall composition of the individual features of the face and if that picture adds up to being a face.
How does Machine Learning work?
Machine Learning looks for patterns in data to inform better decisions in the future. In order to do that the model needs initial input.
So called training data is fed into the model that serves as a base of examples. Training data can be for example a lot of pictures or loads of text, depending on the desired function of the model.
The developers of the Machine Learning algorithm choose a type of learning to use: supervised, unsupervised, reinforcement learning or a combination.
The model trains itself to find patterns and the developer can tweak the model over time by changing parameters.
The steps of developing a Machine Learning model are as follows:
- A problem is defined and a goal is set for the model to achieve.
- The development team chooses their algorithm.
- Training data is gathered: sources of data are identified (for example a cat image database), scripts are written to extract the data (getting the cat images in your own database), data is verified (are these quality pictures of actual cats), cleaned (get rid of mouse pictures) and in case of supervised learning the data is labelled (image = cat).
- The model is built and trained. In a supervised model the team feeds data to the model and tweaks its parameters. In an unsupervised model the team doesn’t interfere with how the model learns and observes the outcomes that the model provides.
- The model is connected to an application so the intelligence of the model can be accessed by end users, this can be anything like an analytics dashboard, search engine or a webshop.
- The final step is model validation: the model is verified based on the output of the model and the user experience in the application. If outcomes are not desirable or if they are degrading over time, the model has to be retrained.
A great way to get a picture of how Machine Learning works is to check out this interactive website:
Visual explanation of Machine Learning by R2D3

Use cases of Machine Learning in recruitment
There are loads of use cases in recruitment for the application of Machine Learning.
The recruitment process exists for a big part on collecting information: finding profiles, screening and scoring them, assessing candidates etc.
Every step in the recruitment cycle can be potentially a very data driven one, that's why you see use cases all across the cycle.
Candidate sourcing and screening
One of the most well known but at the same time challenging uses of Machine Learning in recruitment is in the sourcing and screening process.
Candidate profiles (or CV’s) and in some cases social media activity are analysed to get a better understanding of what background, skills and interest candidates have.
This information is then matched to the job requirements of the hiring company.
The opportunity for using Machine Learning in this process is the speed and volume at which Machine Learning algorithms can analyse data and the statistical accuracy at which they can match profile and activity information to job and company information.
A big part of the sourcing and screening is doing checks based on requirements. The challenge is that talent data is very hard to standardize because candidates in different industries have different ways of articulating and structuring their information and the same accounts for how hiring companies draft their job descriptions and requirements.
Examples of companies in this field are HeroHunt.ai, Ceipal and Beamery.
Candidate assessment
Candidate assessment is used to assess a candidate’s competency. In most cases an assessment is focussed on skills but there are also assessment tools that focus on personality and intelligence.
In some cases it makes sense to support candidate assessments with Machine Learning because assessing skill, personality or intelligence can be a lot more complex than a simple traditional or fuzzy logic algorithm (capable: yes or no, capable score: 1, 2 or 3).
What most Machine Learning candidate assessment tools try to do is to contextualise skills and personality traits to the job that has to be performed. That's a complex task since every single job has its own unique requirements and every company their own culture and needs for certain talent.
Examples of tools in this field are Kandio and iMocha.
Interview automation
The interview is getting more automated with interviewing bots. Candidates are already literally talking to robots, where previously a recruiter would have done the conversation.
When robots are used in the interview process they are usually used in one of the first interviews. They ask the candidate questions but also analyse their responses.
These interviewing bots are far from perfect. MIT Technology Review tested some of the interview bots and found that also with responses in German one of the bots gave a 6/9 for English proficiency.
But even though there are flaws in these technologies, the efficiency and structure at which interview bots can operate are enough reason for quite some companies to make use of the technology already.
Examples of companies in this space are HireVue and myInterview.
Candidate engagement
Candidates need to be engaged in order to get them interested in your company and job. But hiring companies don’t have the time to continuously communicate with candidates.
Therefore companies use technologies like chatbots that mimic real life conversations so candidates can learn more about the company and position before they even talk to recruiters.
Chatbots use Natural Language Processing (NLP) to understand language and formulate logical responses to prompts, questions and answers. Most chatbots are based on language models which learn the more they talk to people.
Examples of candidate chatbots are Mya, Olivia and Jobpal.
Programmatic job advertising
Programmatic job advertising is the distribution of job ads across several platforms like social media and job boards to reach the right candidates.
The goal is to simplify, automate and optimize job ad distribution using data, learning and analytics.
Some programmatic job advertisement platforms are driven by traditional logic, but some include Machine Learning mechanisms to understand (changing) attractiveness from candidates for certain job positions.
Examples of companies in this space are PandoIQ or Smart Dreamers.
The future of Machine Learning in recruitment
Historically, recruitment has not been the fastest adopter of new technologies. Many recruiters see recruitment still as a people business and don’t like the idea of a machine doing the decision making for them.
But the undeniable advantages of Machine Learning can’t be ignored. As with every technology there are the innovators and early adopters on the one hand and on the other the hand late adopters and laggards. If you look at technology adoption from a historical perspective, you see a clear pattern in which late adopters and laggards usually have to adapt at some point to technological advancements. Once they do, they can run into a significant delay compared to peers in the market who have already adopted it and reskilled accordingly.
As mentioned earlier in how Machine Learning works, data is the key component of making it work. No quality data, no learning. It makes sense to look at what kind of data we use within the recruitment domain. You could summarise the data used in recruitment as ‘People data’ although people data also refers to data collected on current employees. Talent data is a more specific term and relates to all data collected about candidates but also the talent market. Talent data mostly used in the recruitment cycle is data on skills, background (education, experience, heritage), interests, personality and preferences like location.
The challenge with this data is that it’s inherently not standardized. Skills are hard to judge on actual skill level, there is a great variety in job titles and the actual meaning of them and personalities are even more heterogenous.
There is a lot of talent data, but the quality of this data (relevancy, accuracy, completeness) is limited. Because Machine Learning requires loads of quality data, this is one of the biggest challenges for Machine Learning to work in recruitment. One of the developments in recruitment is data driven methods. These more data driven approaches might on the long term result in the collection of better quality data through a more structured and ’unbiased’ approach to analysis, interviewing and assessments.
Although Machine Learning is already here, many solutions will still be initially built upon traditional logic based algorithms. Which is fine because traditional logic based algorithms can be better understood by humans which serves as a great basis for further development.
The essential part of the Machine Learning models that are being deployed in recruitment as we speak, is experimentation. Technical experimentation by means of iteration on the learning algorithms but maybe even more importantly experimentation by the user, the recruiters and the candidates themselves.
These experiments are ongoing, but the failure rate is big and these projects usually take very long before they yield valid results.
The advancement of Machine Learning is inevitable, today's challenges scream for solutions that are able to perform at a higher complexity.
There are too many different situations and variables in recruitment to include in the rule book for a traditional algorithm to work. The people business is too complex to build IF this THEN that statements for, so we have to look at alternative technologies.
Algorithms that recognize patterns at a deeper, more granular level and can cope with complexity are a necessity for progress. Anything else has basically already been done.
And because it's deeply embedded in human nature to keep inventing and progressing, the rise of Machine Learning will continue and accelerate.
So now what?
Maybe you’re just trying to wrap your head around Machine Learning and get ready for the future. Or you are assessing Machine Learning solutions and want to be able to ask yourself the right questions.
You might not be an expert in statistics and learning algorithms, but you are in recruiting. You are still smarter than any existing algorithm, at least for now. You can see the context of things behind people and situations and you consider a lot more variables than a machine.
So the question becomes, how can you keep relying on your human abilities and how to best equip yourself with supporting technology?
Here's a suggestion:
1. Define a clear goal
Forget about the technology for a second. The first thing that matters is what you want to achieve. Don't listen to other people's opinions too much, stop quoting Elon Musk and ask yourself what your biggest challenge is now to help solve. Then define in a specific written out goal where you want to get to and by when.
2. Learn
With your defined goal you have the right ammo to start asking questions. To yourself, your colleagues, experts and solution providers. What is the essence of my challenge and what role can play technology in this? How about Machine Learning? Do I really need Machine Learning in the first place? What is the impact of implementing Machine Learning? What is the impact of not doing it (competition, delay, FOMO)?
3. Experiment
Since you can’t rely on the marketing stories the technology providers are telling you and there is a lot more to Machine Learning solutions than one liners can capture, it helps to experiment with several technologies and see what the practical value is of the solution to reach your goal. Go test a hundred (free) solutions. Ask for a free trial, if that’s not available ask why it’s not available. If there’s no free trial, request a demo with your company data. Demand proof of value. Ignore or blacklist providers who don't show you what value is created.
4. Deep dive into the technology
Learn from how the technology is set up and how it’s different from other players in the market. Talk to solution architects and Machine Learning experts who know your industry. Let them explain the underlying mechanism and check for input data, algorithm bias and if the provider can explain how their algorithm comes to its conclusions (if it's not a black box).
5. Continuously review
Keep an eye on how the technology assists you in decisions. It's easy to forget that a machine is doing a big part of the work. Compare current solutions with the new solutions in the market. Keep experimenting. If you don't you'll get behind. Which is fine but just realize how fast things are developing and how many solutions are available.
Further reading
Although the potential is massive, it’s good to point out that projections within Machine Learning and Artificial Intelligence in general have been notoriously opportunistic.
Many well respected scientists and technologists predicted that a human like AI was close, very close. In 1954, an IBM team predicted that natural language translation programs would be realized in three to five years, in 1965 Herbert Simon predicted human-like AI within twenty years and in 1970 Marvin Minsky predicted the same within three to eight years from that time.
Also the consultancy firms more recently joined the magnanimous prediction party. In 2016, PwC predicted GDP would be 14% higher and McKinsey and Accenture forecast similar figures by 2030. Forrester went haywire in 2016 on set the predictions to $1.2 trillion in 2020. But when 2020 arrived they could only report that the AI market was only worth $17 billion. An overestimation of a multitude of 70.
With AI and specifically ML being still under heavy development and not even close to human intelligence, those predictions are clearly opportunistic.
Every honest projection around AI and specifically Machine Learning seems to have a paradoxical character. On the one hand it promises to automate all the things humans don’t like to do and are bad at, but on the other hand inflated expectations get smashed in the real world and with every new development new concern are raised which slow down experiments, learning and progress.
What can slow down the advancement of Machine Learning
The complexity of Machine Learning comes with the volume needed for learning, the ‘black box’ effect and the potential bias in algorithms.
The volume needed to build a learning model are caused by the big datasets needed and the cost of computing on those big datasets. For a learning model to make statistically significant sense the model needs enough volume in data points. Just like every research projects needs a big enough sample size: you need enough proof that a recurring pattern is a result of a meaningful association rather than chance. Acquiring all that quality data can be expensive (for example buying data sets or scraping it yourself) but also processing that data (running the computations) can be a very expensive undertaking since the amount of computations needed increases exponentially with the complexity of the model.
The black box effect is the problem of obscurity (or opacity), meaning that because learning models recognize patterns on their own progressively, the human that created the initial code doesn’t know anymore why the learning algorithm is making certain decisions. Its decisions are not only based on traditional engineering logic (IF this happens THEN do that) but also on what the machine has taught itself including all the variations possible. The fact that Machine Learning applications can be a black box prevents some users and sometimes a significant part of an industry from adopting the technology. Unexplainable is scary, and probably for good reason.
Bias in Machine Learning is primarily caused by how the data is fed into the learning model. The developer is not very much in control of what the learning model makes of it. But the developer is in control of the input data. Because humans decide which data is put into the system and what the initial rules (for example labels) are, human bias can sneak in to the model. When 10 million CV’s are used as training data for the model and the desired outcome is set to ‘highest probability of getting hired in an executive role’, the machine might favour profiles of male candidates in executive positions because historically there’s a clear pattern of more men than women in executive positions. But because that’s historically correct it doesn’t mean that men necessarily do a better job in executive positions. A famous example where this went wrong is Amazon who cancelled an AI recruiting tool after it showed bias against women.
What can speed up the advancement of Machine Learning
As with any integrative technology, advancement is very much dependent on developments in other technologies and human behaviour.
These are some of the developments that can accelerate Machine Learning:
Adoption historically has had an exponential character. When some people start adopting new technologies, then they also start talking about it. When more people talk about it, more people start using it who will on their turn also start talking about it. Innovators and early adopters are driving experimentation in the domain and show that the technology works for their use case, the rest follows.
Perception is changing regarding the ’new’ technology. Where the technology is in many cases still an intruder to people's comfortable jobs and lives, is slowly becoming an addition to life and work and in some cases even a necessity.
Computing is becoming more efficient. Moore's Law states that the number of transistors on a microchip doubles about every two years. Because of this, the cost of computing is basically halved and companies can use more computing power for less. Making Machine Learning more realistic also for smaller companies with less cash.
Talent is slowly catching up with increased demand for talent in AI applications. Talent that has a technical in AI is growing with about 26.5% on a yearly basis (US). Even though it's not even close to the growth of demand it does speed up the creation of meaningful technologies.
Recruit talent on autopilot
Find and reach the best talent through billions of profiles with AI
Start for free

